- Home
- :
- All Communities
- :
- Products
- :
- ArcGIS GeoStatistical Analyst
- :
- ArcGIS GeoStatistical Analyst Questions
- :
- “Densify Sampling Network” – Error by reducing the...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
“Densify Sampling Network” – Error by reducing the monitoring network
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
I am working on optimizing an existing monitoring well network in ArcGIS as part of my master thesis. I successfully used the tool “Densify Sampling Network” for adding measurement locations to parts of the study area with a high kriging standard error. However I can’t manage to use the tool for the reduction of measurement locations for those parts of the study area where they have the least influence on the predictions. I keep receiving "Error 040043: Measurement error for data with coincident samples should not be equal to zero." (As parameters I used number_output_points: 5 and in_candidate_point_features: point feature class containing all 137 monitoring wells). What am I doing wrong?
Thanks for your help in advance.
Best regards
Maurice
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Maurice,
Unfortunately, the workflow for removing points from an existing network requires that the nugget parameter in kriging be interpreted at least partially as measurement error. I will add this limitation to the documentation for Densify Sampling Network.
To resolve the error, you need to alter one parameter of your kriging layer using the following steps:
- Optionally, make a copy of your kriging layer in case you make a mistake.
- Right-click the kriging layer in Table of Contents and choose "Method Properties". This will open the Geostatistical Wizard and allow you to change parameters for that kriging layer.
- Click Next until you get to the Semivariogram/Covariance modeling page.
- In the parameters on the right, find "Measurement Error" (it is under the "Model Nugget" menu). To encounter Error 040043, this parameter must have been set to 0 (if it is any other value, please let me know).
- Change the Measurement Error value to anything larger than 0 but no larger than 100.
- Click Finish, then OK on the Method Report screen. This will update the kriging layer, but it will probably look identical in the map.
- Re-run Densify Sampling Network with the altered kriging layer, and it should now run successfully.
Please let me know if you have any other questions or run into any other problems.
-Eric Krause, Geostatistical Analyst Product Engineer
PS, if you intended to remove 5 points from your network, you should actually use 132 for the number_output_points rather than 5. The five points that are not created by the tool are the stations that can be most safely removed; the 132 points that are created from the tool are the ones that help the most in the interpolation.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Eric,
thank you very much for your quick and helpful answer.
I could now figure out the problem: Unfortunately, I performed kriging as an exact interpolator and therefore didn’t use a nugget at all. So there was no kriging standard error at the measurement locations despite the “Measurement Error” being 100%.
As the tool “Densify Sampling Network” needs a measurement error I altered my isotropic semivariogram model (Type: Stable; Parameter: 1.4; Range: 1,200 m; Partial Sill: 5.86 m) by adding
- (I) a small nugget of 0.01 (that deteriorates the cross-validation results),
- (II) an extremely small nugget of 0.00001 (with negligible effects on the cross-validation results).
Then the tool ran successfully both variants creating two point features classes, each containing the 137 measurement stations in the order of decreasing StdErr values (which I interpreted as decreasing importance). As expected, variant (II) results in smaller StdErr values compared to variant (I). However, the ranking of the 137 stations is similar but not identical: There are minor differences between both rankings with a maximum difference of 5 ranks.
So regarding my target of identifying stations that could decommissioned the tool “Densify Sampling Tool” gives me good hints but I’m not fully satisfied. Originally, I thought of performing the monitoring network reduction in another way:
I intended to use a cross-validation procedure by sequentially removing each of the 137 station to register the increase of the mean kriging standard error of all prediction point locations (nearly 21,000 points on a regular grid). The station leading to the smallest increase of the mean kriging standard error would be decommissioned and I would restart the procedure with the remaining 136 stations based on the new Geostatistical Layer. However, the manual procedure is too time consuming.
But there would be another way leading to the same results more straightforward using the mean kriging weights of the measurement stations: Firstly, the stations with their associated kriging weights for all single prediction point locations need to be determined (which can be done manually for any single prediction point location in the Search Neighborhood page of the Geostatistical Wizard). Secondly, the mean kriging weight of every station would be averaged over all prediction point locations. The station with the least mean kriging weight would be decommissioned and then the procedure is repeated based on the new Geostatistical Layer. Unfortunately, again I see no way other than the absolutely unrealistically manual procedure…
Is there any chance to get one of my two intended procedures automatized? Do you have any advice for my decommission target?
Cheers!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I intended to use a cross-validation procedure by sequentially removing each of the 137 station to register the increase of the mean kriging standard error of all prediction point locations (nearly 21,000 points on a regular grid). The station leading to the smallest increase of the mean kriging standard error would be decommissioned and I would restart the procedure with the remaining 136 stations based on the new Geostatistical Layer. However, the manual procedure is too time consuming.
If you are comfortable using ModelBuilder or making Python script tools, this workflow can be automated without too many headaches. And you can use the kriging model with no nugget without any problems.
I've never done this workflow before, but I think this general workflow will do what you're trying to do:
You'll need to iterate over all 137 points. For each point:
- Create a selection of the other 136 points.
- Use "Create Geostatistical Layer" geoprocessing tool to create a geostatistical layer of the 136 selected points. For the model source, use the kriging layer that was created with all 137 points. This will apply all the kriging parameters from the kriging model to the 136 points. Create Geostatistical Layer is a little tricky to use, but I can help if you run into trouble. Look at the scripting examples in the documentation, and you should be able to figure it out.
- Use "GA Layer to Points" to predict to the 21000 points. Use the geostatistical layer created in step 2. This will create a feature class with the kriging predictions and standard errors at the 21000 points. These predictions and standard errors are calculated only from the 136 selected points.
- Calculate the average of the Standard Error field in the feature class created in step 3.
- Save the average standard error value.
After iterating through all 137 points, you can identify the point whose removal resulted in the smallest average standard error value, and that point can be most safely decommissioned. You would then repeat the above steps for the remaining 136 points to identify the next point that can be most safely decommissioned. Then you would do it for the remaining 135 points, etc.
I'm not an expert in ModelBuilder or Python, but I'm happy to try to help if you run into any problems implementing this automation.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks’ for your help! As I’m quite a novice using ModelBuilder so it took me a while to figure out how to implement the iteration and to write the results in a table. But now I’m happy with the result (attached file: 1_Decommission_Monitoring_Stations).

By now, I’ve tested the model running 12 of 137 iterations. And I can determine that performing all 137 iterations will take about 3 hours (due to the prediction of 21,000 points per iteration mainly).
Implementing the tool “Create Geostatistical Layer” is a little tricky indeed:
- Unfortunately, the Input dataset can’t be connected directly but has to be chosen from a drop-down menu. Here the required Dataset “Input_XY_REF” exists 4 times (attached file: 2_Create_Geostatistical_Layer_Screenshot)! Using trial-and-error I determined the right one: It includes the required selection, so that the candidate is removed from the dataset. (Choosing the wrong ones’ results in using the whole dataset and therefore the standard error staying the same…)
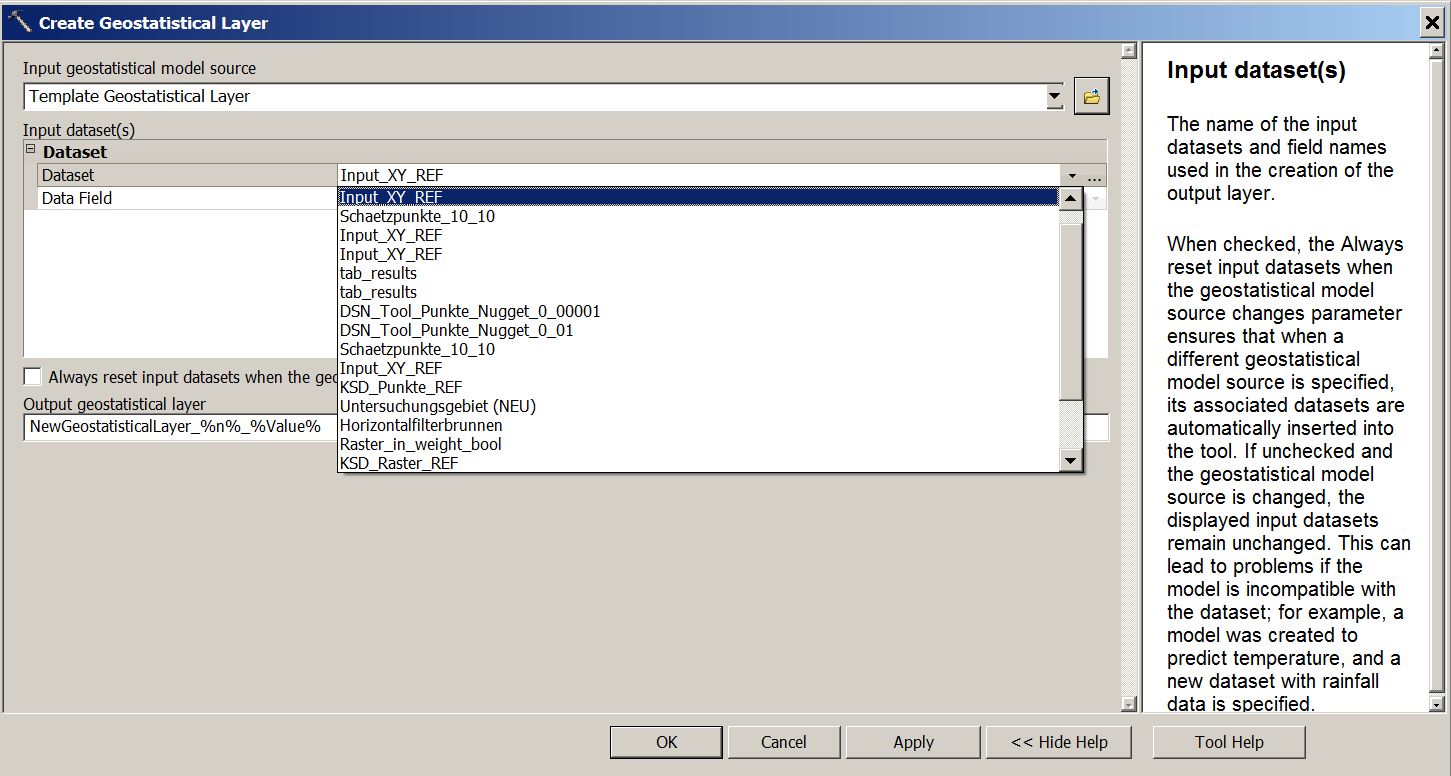
- I’ve decided NOT to check the option “Always reset input dataset when the geostatistical model source changes” as I think my Template Geostatistical Layer won’t have to change at all. Am I right?
Best regards, Maurice
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
As far as I can tell from the graphic, everything looks good. And, yes, you can safely uncheck the "Always reset input..." option.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Since you seem to have a good understanding of kriging, I'll try to explain why you originally got the error that you encountered. Densify Sampling Network was originally designed only to add new locations to an existing network. It was only later that we realized that you could also use it to decommission stations by using the original points as the candidate locations. However, when you implement this workflow, the software must keep all of the original points in order to calculate the standard errors when each new point is added. So, when you add the first point, it actually creates a coincident point because you still have all of the original points. When this happens, if your kriging model does not have a nugget or if the nugget is interpreted entirely as microscale variation (ie, not measurement error), then the software does not know how to reconcile this contradiction, and you receive the error.
This limitation is frustrating, but unfortunately I don't think there is any way to get around it.