- Home
- :
- All Communities
- :
- Products
- :
- Geoprocessing
- :
- Geoprocessing Questions
- :
- Multiple Ring Buffer Error
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Multiple Ring Buffer Error
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I keep running up against an error where after running the MRB tool on a point shapefile or a point geodatabase feature class, I get an error code of 000210 because a file, "union.shp.shp" is invalid and can't be exported to the scratch workspace. How do I get around this?
Attached is a picture of the error.
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You can't save a shapefile (*.shp) inside a GDB feature class. Remove the .shp from the output file name, or save the shapefile in a folder instead.
edit: I'm not exactly sure how you're specifying the output. Can you post a screen shot of the MRB buffer tool dialog just before you run the tool?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Darren,
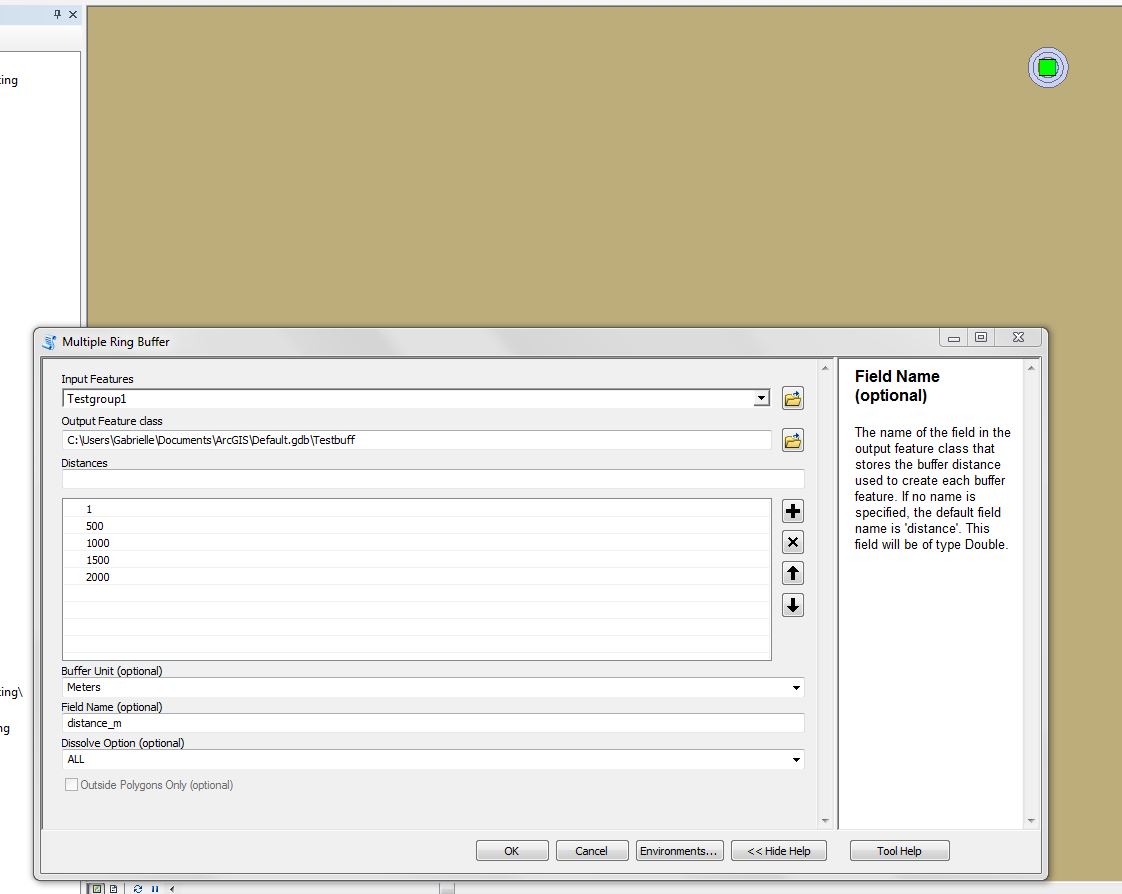
Thanks for your help. For some reason, when I run the buffer tool on a different computer, the output works and I have no problem. The buffer shapefile (Testgbuff) is able to be stored in the Default geodatabase and there is no more issue with the intermediate shapefiles being created and stored in the scratch geodatabase. Attached is a picture of the inputs I used for the tool as well as a visualization in the upper right corner of the rings created.
Do you know what changed to make the script work now as opposed to before?
Also, I have a python script that is supposed to run through these and other processes for a much larger set of points. I've been using the manual tools to try to trace back the issue but I am still receiving errors when running the script. I'll post the script I'm using and the error I'm receiving below this reply.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
# set the workspace to whatever location this code is in. So as long as the code and
# the database are in the same place, this code can be run.
import os
#arcpy.env.workspace = os.getcwd()
# Allows Arc to overwrite files if a file with the same name already exists.
arcpy.env.overwriteOutput = True
# Since the initial data processing may have a few steps that can't be done in Python,
# this is what to run once you have the points layer with the necessary fields.
# Set the layers we're working with.
gaugePoints = "Testgroup1" #This is the river gauge points feature class.
rivers = "courses" #This is the rivers feature class
elevationLayer = "SRTM90_V4.elevation.tif" #This is the elevation raster.
def calculateMaxHead(RFID, GFID):
riverIDCDA = str(RFID) #Converts parameters to a string.
pointName = str(GFID)
# These expressions are a bit tricky. Check the tables and adjust accordingly.
# Preferably, use fields that are numeric types.
riverClause = ''' "IDCDA" = '''+riverIDCDA #For picking out a single river
pointClause = ''' "FID" = '''+pointName #For picking out a single point
#Sets objects and file names.
river = "River1"
gauge = "Gauge1"
bufferFileName = "Rings"
headFileName = "HeadPoints"
headFileName2 = "HeadPointsSingle"
elevationFileName = "ElevationPoints"
statsFileName = "MaximumHead"
#Selects the river and the point.
arcpy.Select_analysis(rivers, river, riverClause)
arcpy.Select_analysis("Testgroup1", gauge, pointClause)
#Generates the multiple ring buffers for that point.
#500 m intervals, the 1 m buffer is to include the point itself.
arcpy.MultipleRingBuffer_analysis(gauge, bufferFileName,
[1,500,1000,1500,2000], "Meters", "distance_m")
#Generates the points of intersection between the buffers and the river.
arcpy.Intersect_analysis([bufferFileName, river], headFileName,
"ALL", "", "POINT")
#Converts the multipoint output of intersect into single points.
arcpy.MultipartToSinglepart_management(headFileName, headFileName2)
#Extracts elevation values from the raster to the points.
arcpy.sa.ExtractValuesToPoints(headFileName2, elevationLayer, elevationFileName)
#Runs summary statistics to get the range of elevation.
#Picks out that statistic from the table using a cursor.
arcpy.Statistics_analysis(elevationFileName, statsFileName, [["RASTERVALU", "RANGE"]])
cursor = arcpy.SearchCursor(statsFileName)
headMax = 0
for x in cursor:
headMax = x.getValue("RANGE_RASTERVALU")
return headMax
#Iterates over the entire table and calculates head for each point.
fields = ["IDCDA", "FID", "Head"]
with arcpy.da.UpdateCursor(gaugePoints, fields) as cursor:
for row in cursor:
r = row[0]
g = row[1]
row[2] = calculateMaxHead(r,g)
cursor.updateRow(row)
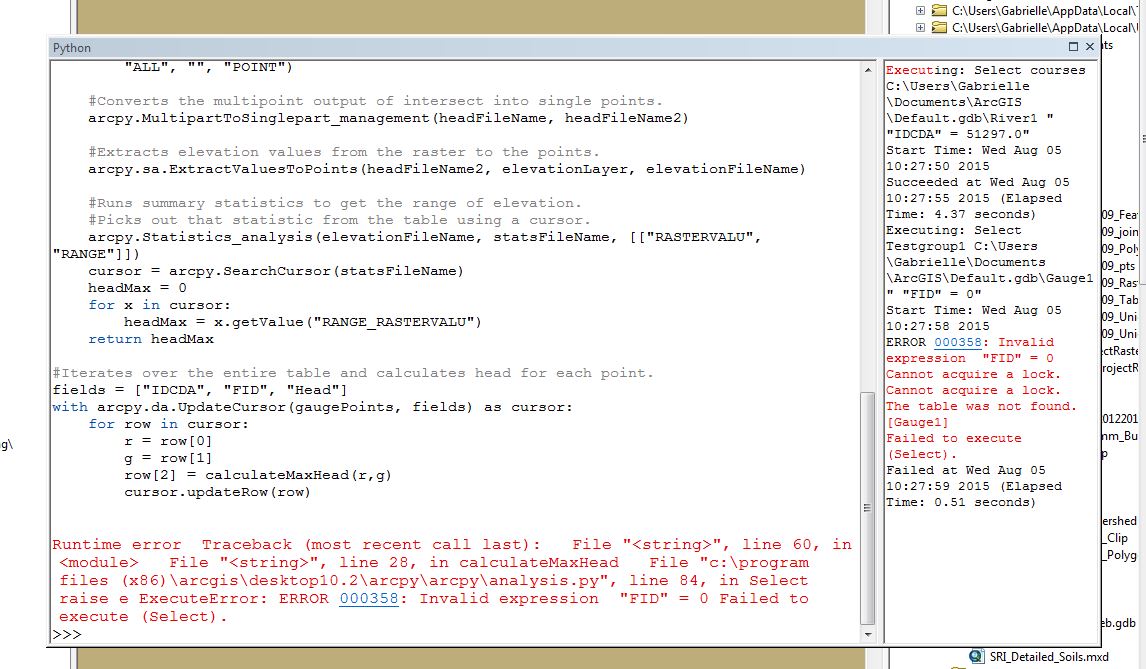
Here is the error reading I get when I run the code:
The script basically sets an initial starting point, generates heads (difference in elevation between two flow points in a river) based on end points set at regular (Euclidian) length intervals from the start point (out to 2 km), then moves the starting point and repeats the process.
I'm not sure what "cannot acquire a lock" means or hwhy "FID"=0 is an invalid expression. I'm realtively new to using ARcGIs and especially Python in ArcGIS so any help/explanations are appreciated.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
There would seem to be a problem with your where clause. Joshua Bixby makes a good point about using python string formatting in this thread Python - Select by attributes query issue. I would suggest you take a look at make sure your expression is working properly.
Further reference on python string formatting can be found here:
7.1. string — Common string operations — Python 2.7.10 documentation
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
As Ian Murray points out, Python string formatting would really come in handy in this situation. There are so many single and double quotes in those SQL statements, it will be hard for anyone but the author to follow or maintain that part of the code.
Looking at a couple snippets of your code, I think I can illustrate what is going wrong.
>>> GFID = 0
>>> pointName = str(GFID)
>>> pointClause = ''' "FID" = '''''' "FID" = '''+ pointName
>>> print pointClause
"FID" = "FID" = 0Interestingly enough, your code generates a slightly different pointClause expression when I copy and paste it into the interactive Python window. That said, the expression is invalid either way. At this point, I am not sure what to suggest because I am not exactly clear what you are trying to select. For example, are you simply trying to FID = 0 or are you trying to add some values together before selecting.
If you are trying a simple FID = x type of selection, the Python string formatting looks like:
>>> GFID = 0
>>> pointName = str(GFID)
>>> pointClause = "FID = {}".format(pointName)
>>> print pointClause
FID = 0For the Select tool, and most other tools, the field name doesn't need to be quoted or escaped. Building expressions for the Calculate Field tool is a bit different than building where clauses for most other tools. I find that commonly trips users up when going back and forth between building expressions and where clauses.