- Home
- :
- All Communities
- :
- Products
- :
- Geoprocessing
- :
- Geoprocessing Questions
- :
- Re: Split function leading to missing polygons
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Split function leading to missing polygons
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I've been trying to use the Split function to split a shapefile into multiple shapefiles based on its polygons. However, when I use the function, shapefiles are created from many of the polygons, but a handful are missing. There doesn't seem to be any pattern based on the Field I'm splitting by (i.e., no strange symbol is present in the NAME field) among the missing polygons, and I've tried Repairing Geometry just in case to no avail. Do you have any idea what might be going on?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This is split in ArcMap Split—Help | ArcGIS for Desktop
This is split by attribute in PRO Split By Attributes—Help | ArcGIS for Desktop
and its version in ArcMap for shapefiles http://www.arcgis.com/home/item.html?id=15ca63aebb4647a4b07bc94f3d051da5
So what are you splitting? by attributes or geometry? in arcmap or pro?
Have you run a multipart to singlepart on the file first ? ie Multipart To Singlepart—Data Management toolbox | ArcGIS for Desktop
Can you provide a picture of where things aren't working.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I've looked at the Split Help sites, and could not find the Split by Attributes function in my program--is this something I need to use Python for? I'm running ArcMap and trying to split by attributes, particularly one specific field. I have a shapefile of neighborhoods in a city, each neighborhood polygon with its own ID number, and I'm trying to split the shapefile into multiple shapefiles for each neighborhood. Essentially, when I run the Analysis > Split function to split by the ID field, it creates 80 of the 89 neighborhood shapefiles, but inexplicably does not create the other 9. I did not run multipart to singlepart, but I added all values of the field (ID) I wished to split by in the Layer Properties > Symbology > Categories window. Thanks!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
What Dan Patterson is pointing out is that there are several ways to do a split, but without some more details on your part it will be impossible to come up with a solution.
For example, which program are you using? ArcMap? ArcGIS Pro? Arcview? Something else?
And what version? Functionality sometimes changes between versions.
If you can provide more information, that would help greatly in troubleshooting this. This can include not just words, but visual information. Take a snapshot/screenggrab of the attribute table. Take a screenshot of the program. Add them to your post.
Chris Donohue, GISP
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I'm running ArcMap within ArcGIS 10.3.1 for Desktop. I've attached my original shapefile with all its features in the ToC on the side, as well as the shapefiles that result from the Analysis > Extract > Split function (the white spaces are missing neighborhoods). The third image is how I'm setting up the Split function (I'm splitting by name of neighborhood, which are all unique). And the fourth shows the attributes of the file I'm splitting.
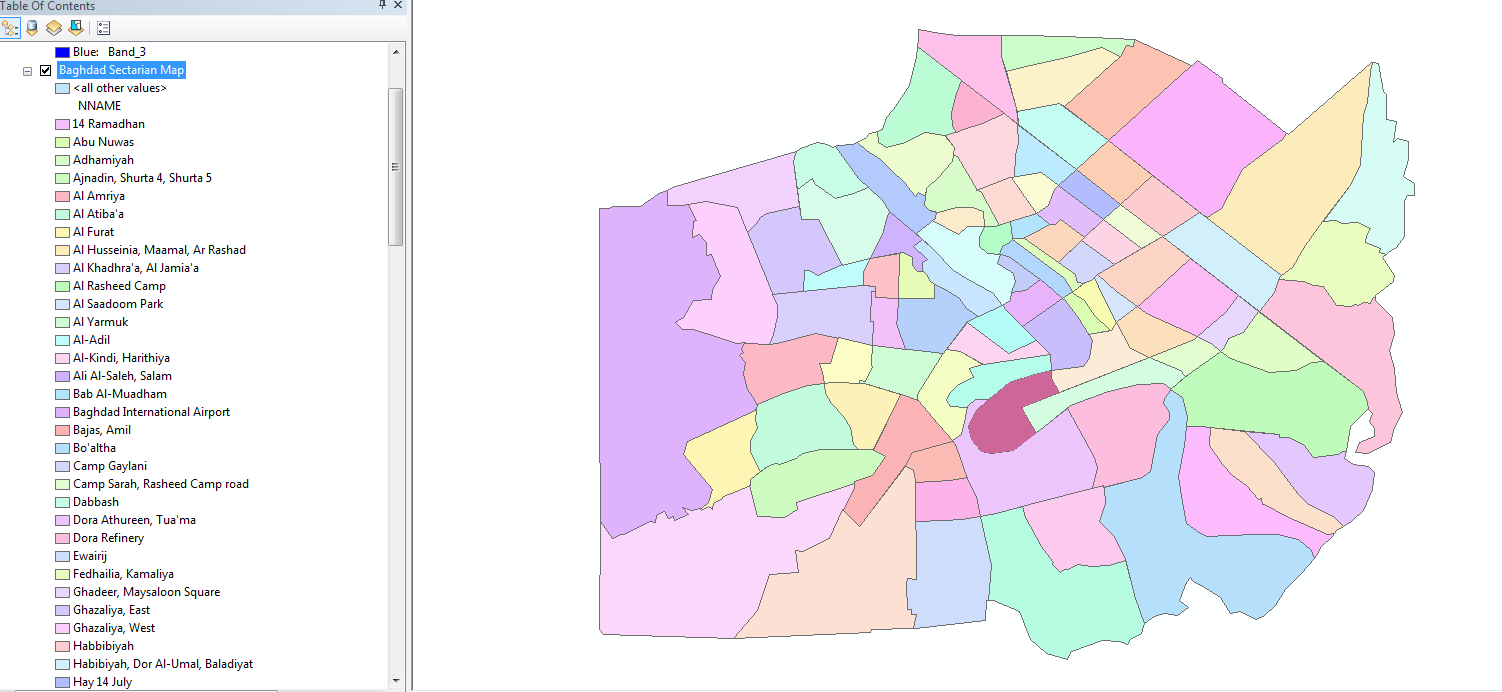
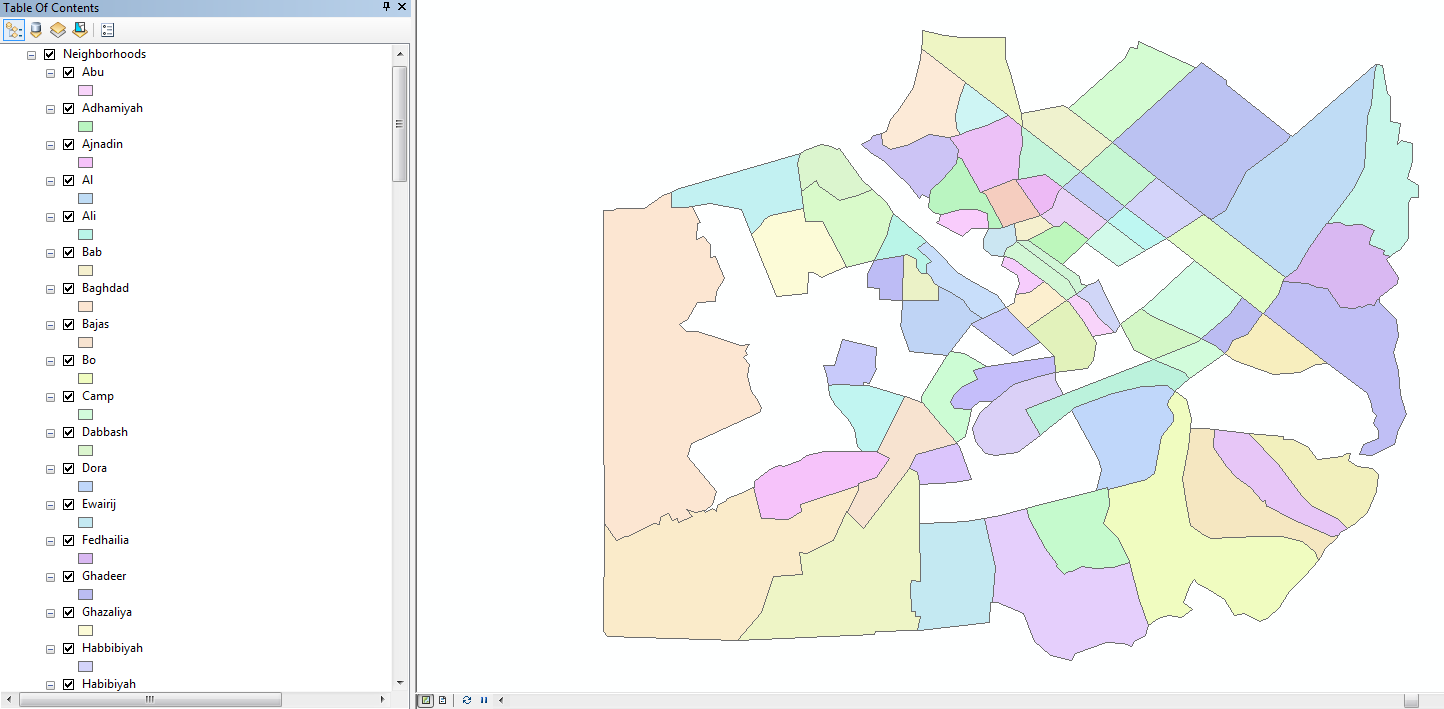

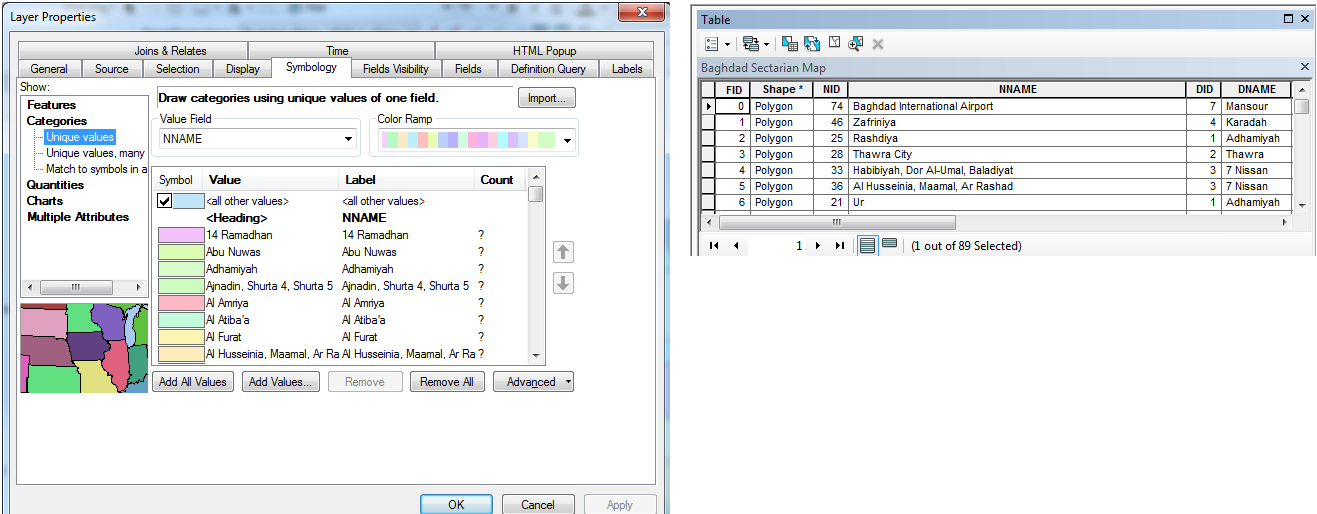
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I figured it out--for those interested, Split only allows a text field to be the input, which is why I used NNAME field (the names of each of the neighborhoods). However, it seems like the names of the neighborhoods were too complicated/long for ArcGIS, so some of them were not being processed by Split. I ended up creating a new Text field with the unique ID numbers starting with a letter (i.e., N_1, N_2, etc.) and successfully running the Split function with that input instead.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
glad it worked out. I am surprised that it didn't throw an error since the destination for the split was in a geodatabase and at least one of your unique records in the field started with a number. From the split help...
- The split field's unique values must start with a valid character. If the target workspace is a geodatabase, the field's values must begin with a letter. Field values that begin with a number as in "350 degrees" cause an error. Exception: Shapefile names can begin with a number, and a folder target workspace allows field values that begin with a number.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Sara. I'm having the exact same problem as you were, but I'm wondering if there was anything else you did differently between the tool not working and then working. The reason I ask is two-fold: one, my random outliers do not have numbers or spaces as the first character; and two, the field type (text vs number) is determined for the entire column, not individual rows. I also tried isolating the 11 polygons whose geometry did not produce an output and re-running the Split tool, but to no avail. I'm just hoping I can narrow it down some more, because the behavior and randomness of it is so bizarre, as you clearly understand. Thanks!
P.S. The Split that I'm doing is on census blocks using school boundaries as the Split Features. As you can see, the vast majority worked just fine, and in many cases had longer names in the Split Field than the rows that didn't work, hence my inquiry about whether anything else was done differently. Thanks again!
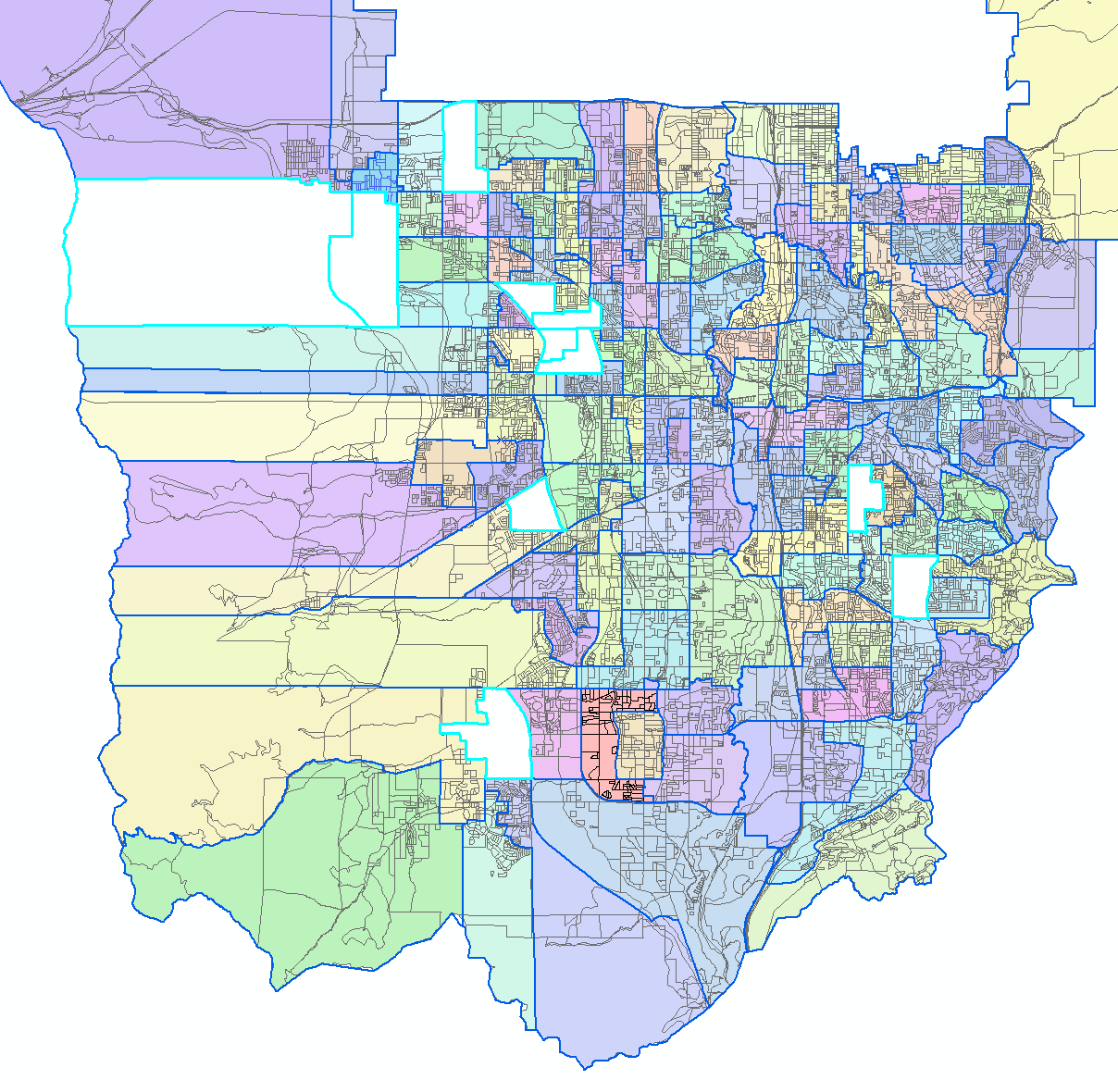
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
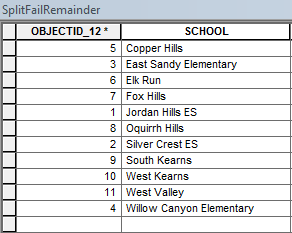
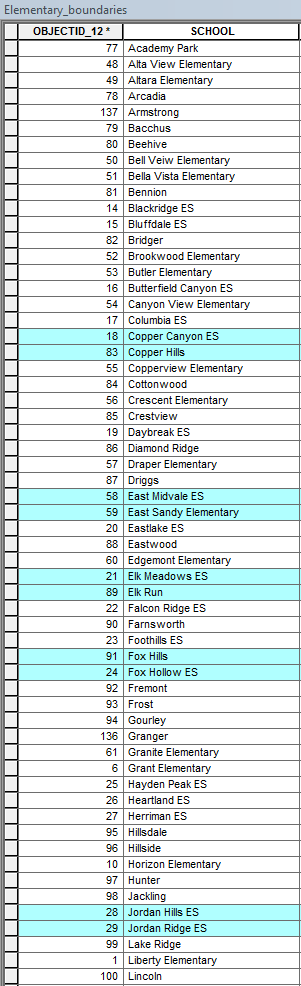
Okay, so I kept digging and found the most likely cause of the problem. Two things are happening here, and frankly, I think they are both flaws that Managing Data (Esri) should look into. The first part of the problem is that the Split (Analysis) tool only uses the first word in the Split Field, so that "Altara Elementary" simply becomes "Altara" in the output. The second problem is that it eliminates (seemingly randomly) any additional rows with the same first word from the output. Thus "Copper Canyon ES" and "Copper Hills", both being truncated to "Copper", evidently cannot coexist, and one is dropped from the output (in this case, "Copper Hills").
Based on the 11 features that failed to produce an output (see "SplitFailRemainder" table), it appears at first glance that the row with the lower OBJECTID (i.e. the one that is detected first if starting at 1) is the one that gets to stay; however, randomness strikes yet again when we get to "Jordan Hills" and "Jordan Ridge", because as you can see in the "SplitFailRemainder" table, "Jordan Hills ES" is the one that failed to produce an output, but it originally had the lower OBJECTID of 28 (see "Elementary_boundaries" table). This anomaly occurs with two other words/names from my list, but the rest of the duplicates are eliminated by whichever has the higher OBJECTID.
So my workaround was very similar to yours, except that I really wanted to maintain the school name as the names for the output features; therefore, instead of adding a new field, I simply removed the spaces from the school names using the Python parser !myfield!.replace(" ","") in Field Calculator, and that kept the names distinct so that none were truncated or omitted.
But again, I think this is flawed functionality that would require these workarounds for something as relatively simple as this. Thanks for your post on this subject and all who responded. It was exactly the info I needed.
P.S. The "isolation" of the 11 polygons I mentioned in my first post most likely didn't work because I was only using a definition query to isolate. My guess is that if I had exported those 11 rows to a new feature class, they would have Split just fine (with the exception of duplicates, of course). Either way, I needed to run the Split on all 133 features to get the names I wanted, so it worked out anyhow.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Sara,
I am facing the same problem, but the split is not working at all, the outcome of the (split) tool was a bit funny, as I didn't get all of the polygons(I only got like 5% or less of my entire polygons)
Anyone Can Help me in
Note: I have tried the editor in ArcMAP, the cut polygon tool, and tracing option . it worked perfectly, but the problem is that I have so many polygons and it would take so much time. I need something similar to this tool but more automated.
Thanks