- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Re: What sorcery is this?
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
import arcpy
arcpy.env.overwriteOutput = True
fc_in = 'E://SUT//Thesis//Geodata//Thesis.gdb//NRW_Gemeinde'
fc_in2 = 'E://SUT//Thesis//Geodata//Thesis.gdb//NRWCommuterData2'
fc_in3 = 'E://SUT//Thesis//Geodata//Thesis.gdb//NRWGemeindeDissolveFinal_SpatialJoin'
dct = {} #Dictionary for gemeinde-workers pair
dct2 = {} #Dictionary for gemeinde-value pair
dct3 = {} #Dictionary for gemeined-result pair
dct4 = {} #Dictionary for caseID-result pair
dct5 = {} #Dictionary for sub-region origin and destination pair
dct6 = {} #Dictionary for case_ID and result pair
lst = [] #List for case IDs
fld_gemeinde = 'GEN'
fld_workers = 'Workers'
fld_result = 'Result'
fld_o = 'GEN'
fld_d = 'GEN_1'
fld_caseID = 'Case_ID_Ne'
fld_caseID2 = 'Case_ID'
fld_value = 'Value'
fld_sub_region_o = 'Sub_Region'
fld_sub_region_d = 'Sub_Regi_1'
with arcpy.da.SearchCursor(fc_in, (fld_gemeinde, fld_workers), sql_clause=(None, 'ORDER BY "GEN" ASC')) as cursor:
for row in cursor:
dct[row[0]] = row[1]
arcpy.AddField_management(fc_in2, fld_result, 'DOUBLE')
with arcpy.da.UpdateCursor(fc_in2, (fld_o, fld_d, fld_caseID, fld_result, fld_value), sql_clause=(None, 'ORDER BY "GEN" ASC')) as cursor2:
for row2 in cursor2:
if row2[2] in lst:
row2[3] = (row2[4] + dct2[row2[2]])/dct[row2[0]]
dct2[row2[2]] = row2[4] + dct2[row2[2]]
dct4[row2[2]] = row2[3]
else:
row2[3] = row2[4]/dct[row2[0]]
lst.extend([row2[2]])
dct2[row2[2]] = row2[4]
dct4[row2[2]] = row2[3]
cursor2.updateRow(row2)
arcpy.AddField_management(fc_in3, fld_result, 'DOUBLE')
with arcpy.da.UpdateCursor(fc_in3, (fld_caseID2, fld_result)) as cursor3:
for row3 in cursor3:
row3[1] = dct4[row3[0]]
cursor3.updateRow(row3)
Clearly the two lines in the code in bold means that the two circled values in the image should be same. But they are not ! I feel like my head will burst open trying to figure why. Please can some help me?
Solved! Go to Solution.
{kind=link}
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I just realized that in fc_in2 there are more rows with caseID 1 5 further down below. I thought there were just two rows on the very top as seen in the image. That's why I was saying the Result from this second row must be written to fc_in3. But now I see the final updated Result value for rows with caseID 1 5 is in the last row with that caseID (which is further down in the table) and not in the second row. This value is correctly written to fc_in3. I was sorting the table with the GEN field that's why I did not see the rows with caseID 1 5 other than the first two and didn't scroll down to check if there are more. Everything is fine now. The script was correct. And your explanation as well. Thanks alot for your time. I will be careful with the sorting order next time.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Here is the code in PythonWin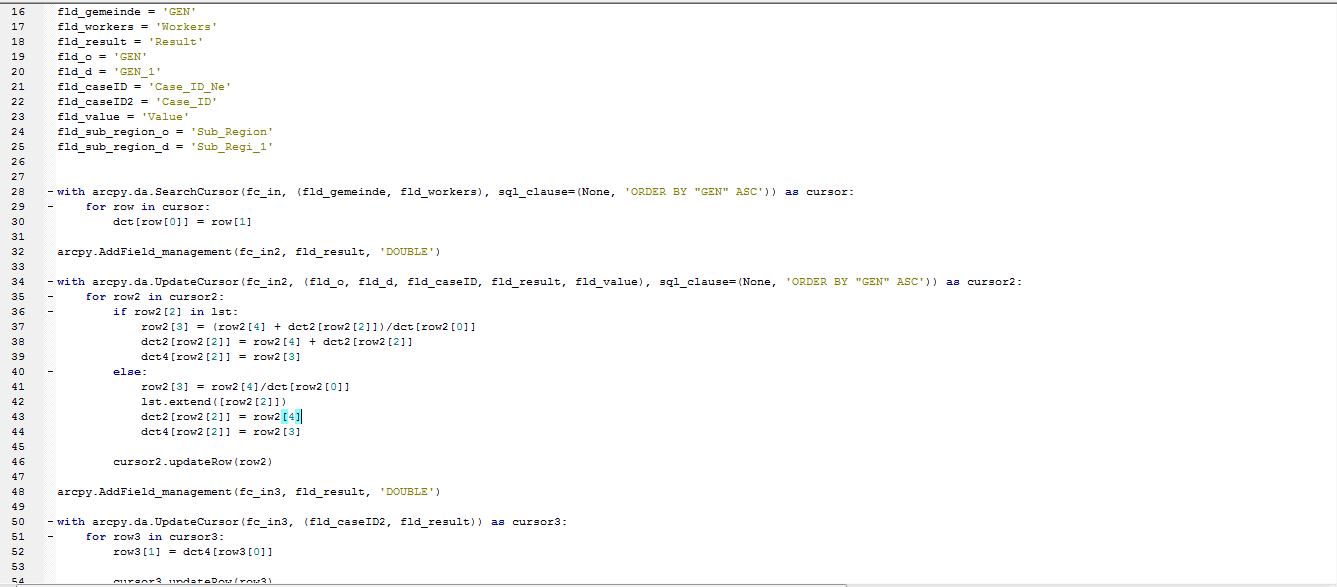
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
From your code, there's no guarantee that you've correctly assigned fld_caseID and fld_caseID2
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I just re-checked it once again. They are correctly assigned.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The results written to fc_in2 are based on the records read until that moment. The result written to fc_in3 are based on dct4 after all the data in fc_in2 have been processed. Therefore, you wont have the same result for these two featureclasses.
During cursor on fc_in2:
# caseID in list
# result = (value + dct2[caseID]) / workers
# dct2[caseID] = value + dct2[caseID]
# dct4[caseID] = result
# caseID not in list
# result = value / workers
# add caseID to list
# dct2[caseID] = result
# dct4[caseID] = result
For each row the result of that moment will be written to fc_in2. However the result corresponding to dct4 for key caseID keeps getting updated. In case you want to get the same result in both featureclasses AND the result in fc_in3 is correct, the second cursor should be a search cursor to generate dct4 and afterwards you should do an update cursor to on fc_in2 to set the result values from dct4.
Maybe some more explanation on what you are trying to obtain could be helpful. And the workers are not shown in the image. If you could attach the data, people can have a better understanding of what is going on.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes you are correct, dct4 for key caseID keeps getting updated as the update cursor moves on each row in fc_in2. But after that I need these updated values from dct4 to be written to fc_in3 in the result field. Thats why I first run update Cursor on fc_in2 - this updates dct4 and gives each caseID a result value (in dct4) and then Im trying to write this result to fc_in3 using caseID from dct4 in result field. So it should be same.
Concerning what Im doing, I have multiple rows with same caseIDs in fc_in2 as you can see. For example the first two rows have caseID 1 5. So I want to calculate the result for the first row using value and workers (from another table). Then when the cursor moves to the second row which has the same caseID, it should take its value, add to it the value from the previous row (since previous row had the same caseID) and divide this sum with the workers value. So this second row will have a new value in the result field. This is the updated final value for caseID 1 5 and it will be written in dct4 with that caseID as key. If there are more rows with same caseID then this process should continue. Now I just want to write this same value in fc_in3 for the row with caseID 1 5. In fc_in3 there is just one row for each caseID. Thats the difference. Im outside now I can attach the dataset in the evening probably.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
So effectively if there are 10 rows with same caseID in fc_in2, then the updated result of the 10th row should be written to dct4 for that caseID as key. And I simply want this final result to be also written to fc_in3 for the row with that same caseID by running a last update cursor on fc_in3.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
By the way fc_in2 is not really a feature class its just a geodatabase table. fc_in3 is a feature class.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for clarifying, but since the geometry is not used it does not influence the result.
Question: is the result what you expect it to be or does it require changes. If so, could you attach a sample of your data and specify with more detail what you are trying to achieve?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I just realized that in fc_in2 there are more rows with caseID 1 5 further down below. I thought there were just two rows on the very top as seen in the image. That's why I was saying the Result from this second row must be written to fc_in3. But now I see the final updated Result value for rows with caseID 1 5 is in the last row with that caseID (which is further down in the table) and not in the second row. This value is correctly written to fc_in3. I was sorting the table with the GEN field that's why I did not see the rows with caseID 1 5 other than the first two and didn't scroll down to check if there are more. Everything is fine now. The script was correct. And your explanation as well. Thanks alot for your time. I will be careful with the sorting order next time.